

Fully utilise all bottlenecks
Doing things in parallel has often been stressed, and will indeed improve performance dramatically. The Async – Await methods and the Task and Parallel classes are great in making this easy, and should become habitual on-the-fly solutions. In some cases it is beneficial to plan ahead and use architecture to achieve the full potential.
Example
Consider a process that must do the following:
- 1 Read a file from disk
- 2 Validate the file (e.g. check signage certificate)
- 3 Decrypt or decompress the file
- 4 Process the file (resample, or do some calculations)
- 5 Store statistics in a (remote) database
- 6 Store the processed file in an archive directory
- 7 Delete the original (processed) file
Steps 2, 3 and 4 will be processor intensive.
Steps 1, 6 and 7 are more dependent on the physical storage.
Step 5 is mostly impacted by network latency (or database load).
Bottlenecks can be machine specific
Performance of each resource can vary from machine to machine. The processor (multicore or not), physical storage (solid state or magnetic hard disk) and network (wifi, wired / local or remote datastore) will all be bottlenecks for different timespans on different machines.
If all steps are done in sequence then all of these will be the only bottleneck at their own point in time. When looking at the stats in a profiler, it could well be that none of these will jump out as being an obvious bottleneck (if the jobs are small enough). The meters (in process explorer or other performance analysers, like the top chart of the Ants Profiler) always average utilization over a period of time. In practice they only have two values, working or sleeping. Well… there may be speed-step processor things going on and so, but in general it’s more binary than the 0-100% scale of the meters. Also note that the 100% position of physical disk meters is usually the speed of their cache memory, and thus these will never show 100% utilization for an extended period of time.
A practical solution
One technique I often use, is placing queues between each step. These queues buffer tasks between separate threads that specialise in utilising one of the (potential) bottleneck resources.
Here is a graphical illustration of the concept, where each red box is a single thread:

The processor intensive jobs can have multiple threads processing the same queue in parallel (for example step 4). I tend to make this configurable since it depends on the number of processor cores on a machine if an extra thread would actually help or just cause more context switching overhead. Some profiling can be done internally (without an external tool) by checking which queues fill up on a specific machine. A production server will usually show different results than a developers laptop. The individual maximum queue length is also a good candidate to be made configurable, but is only worthwhile when enough feedback is given (a small UI with progress-bars can make operators very happy).
Things to consider
There are a few caveats that must be avoided.
Memory usage
Before pushing a task into the next queue, a thread should check the current size of that queue and consider sleeping a while if there are too many unprocessed jobs there, or else internal memory may become a problem.
Disk I/O
A less obvious catch is that steps 1, 6 and 7 might actually dramatically decrease the overall performance when they operate simultaneously. Particularly when the source (step 1) and archive (step 6) are on the same physical (non ssd) hard drive. The heads would be rapidly jumping back and forth to the positions of the different files. For this cause let these three steps run in a single File IO thread that will process them in sequence. Steps 6 and 7 might need a higher priority than step 1 when processing in order to release memory, but this can vary depending on the job sizes. If step 6 is done to a different physical disk, then running it in its own thread could be beneficial. The added complexity of implementing such intelligence should be well weighed.
Transactionality
When the operation needs to be transactional, special care should be taken to prevent duplicates or loss of data when the process is killed in mid-flight. If there are multiple database operations spread over discrete steps in the process that need to be done in a single transaction, it might be tempting to include the transaction in the job object passed between queues. I have not done extensive research or benchmarks and I might be wrong, but my guess is that, the database will not be happy when keeping multiple transactions open while they are queued up in buffers. In such cases I usually trade off some parallelism for more discrete and atomic database transactions.
In the example above, a duplicate caused by a previously killed process (or network disconnect) would only be detected at step 5 or 6. An extra step could be added to detect these earlier. Also consider moving files with errors to a seperate directory.
Scalability
When multiple machines should be doing the same work in seperate processes, then the main thread should be a little more sophisticated. It should flag files as being processed in a common database using unmistakenable ID's, and should also ignore files already claimed by another process. This is no different than with any other method of processing, but the chance of having multiple orphans (claimed but unprocessed files) will be allot greater when using this queue buffering technique.
Demo App
Check out my Open-source Batch Image Resizer utility that visually demonstrates this principle. It has some gauges that visualize the current queue length (in red) and the peak queue length (in yellow). The settings (max queue length and number of threads) can easily be tweaked to see how they impact the load and performance between the queues. Another way to balance the load differently is to enlarge a batch of thumbnails (loading is faster, saving slower).
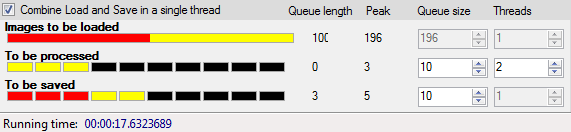
In the source you will find some classes that might be useful to get you a jump start in your own projects. I have bundled these in the module QueueWorkers.dll which I'll document in a future blogpost (when I find the time).
My blog post is an extension of my performance tip featured in ’52 Tips & Tricks to Boost .NET Performance’, where you’ll find 51 other helpful points. Download it for free.